UX RESEARCH CASE STUDY
Confirming what I already suspected — rigorously.
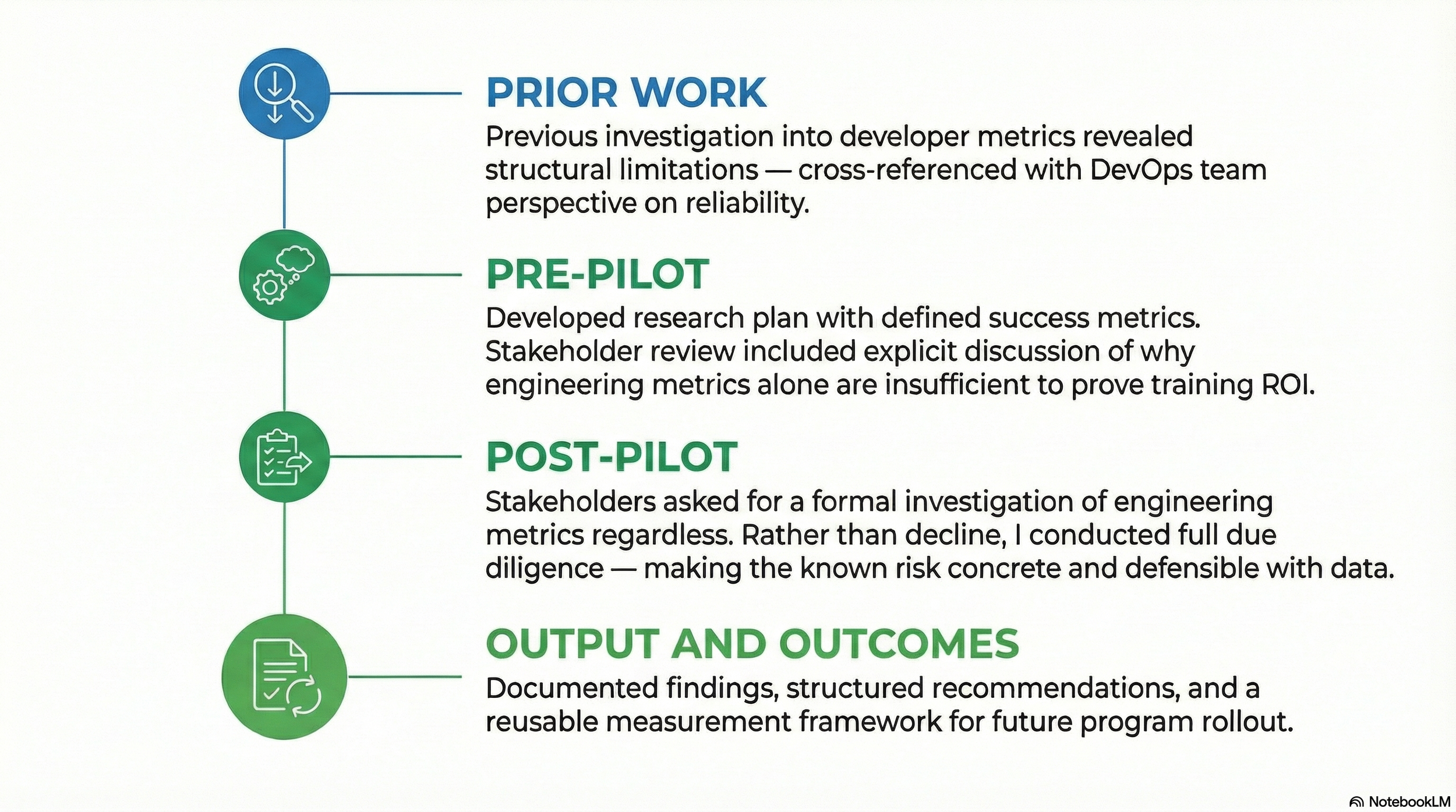
Brought into a mid-flight planning for an AI training pilot with limited control over participant selection, I documented early risk, set defensible success criteria with stakeholders, and when asked to investigate Engineering metrics (post-pilot) as ROI evidence, did the work anyway so I could provide answers that were concrete and actionable.
Role: Lead, UX Researcher & Strategist
Methods: SME Interviews | Data Investigation | Synthesis
Tools: Jira | GitHub | Code Climate
Outcomes: Strategic Measurement Framework & Recommendations
01 — PROJECT OVERVIEW & CONTEXT
Inherited constraints and a clear-eyed start
My involvement in this project began mid-planning. Engineering leadership had already hand picked groups of participants for the AI for Agile SDLC pilot before I came on as project lead and researcher. So, the participant pool was set, chosen by leadership — not research criteria —which meant I was working within constraints that weren’t mine to define.
Rather than treat this as a blocker, I worked within those constraints thoughtfully. One of the pilot’s primary objectives was driving GitHub Copilot adoption, so I focused on participant segmentation on what I could influence with what existed: ensuring the group represented a meaningful spectrum of current usage. Across the cohort, I wanted to look at engineers with no GitHub Copilot license, those with a license but low adoption, and those using the tool regularly. I felt this would give the pilot a meaningful adoption gradient to work with, even if the overall cohort structure wasn’t optimized for clean measurement.
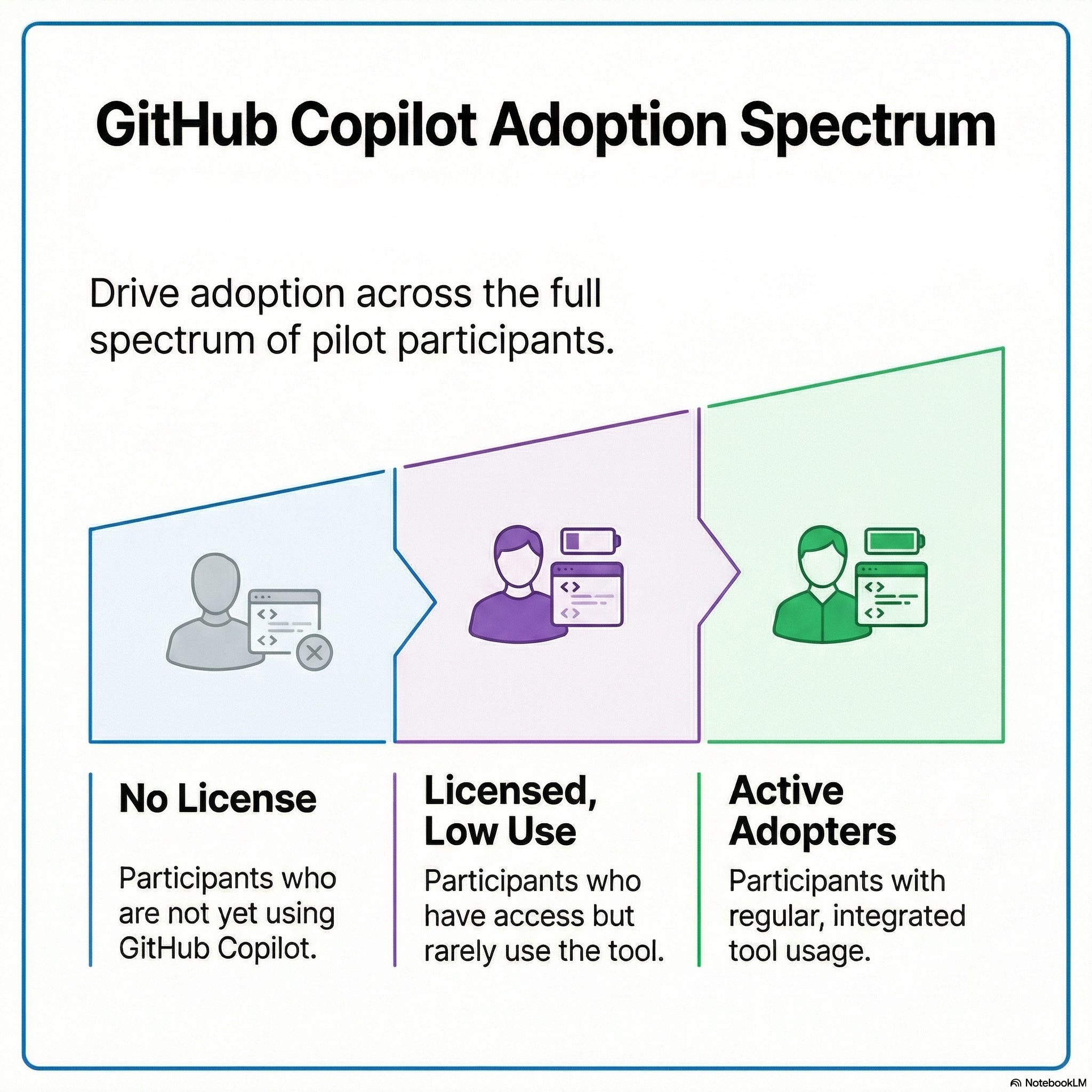
02 — RESEARCH GOALS & EARLY RISK AWARENESS
Known risks, documented early
03 — RECRUITMENT & METHODOLOGY
Who I talked to and why
When the post-pilot investigation was requested, I approached it the same way I would any research engagement: with structured conversations, documented findings, and a synthesis process. I identified three domain experts representing the questions and platforms in scope.
01
Making the known constraint concrete
The goal of this analysis wasn't to discover something new, it was to document and substantiate what prior experience and stakeholder conversations had already surfaced. Translating a known professional judgment into a data-backed, documented conclusion is its own form of research rigor.
I investigated team-level data across all three platforms directly, looking for any evidence that countered the hypothesis that measurement was unreliable. I found none and catalogued exactly why, across two dimensions: structural barriers in the systems themselves, and analytical barriers in how the data behaved.
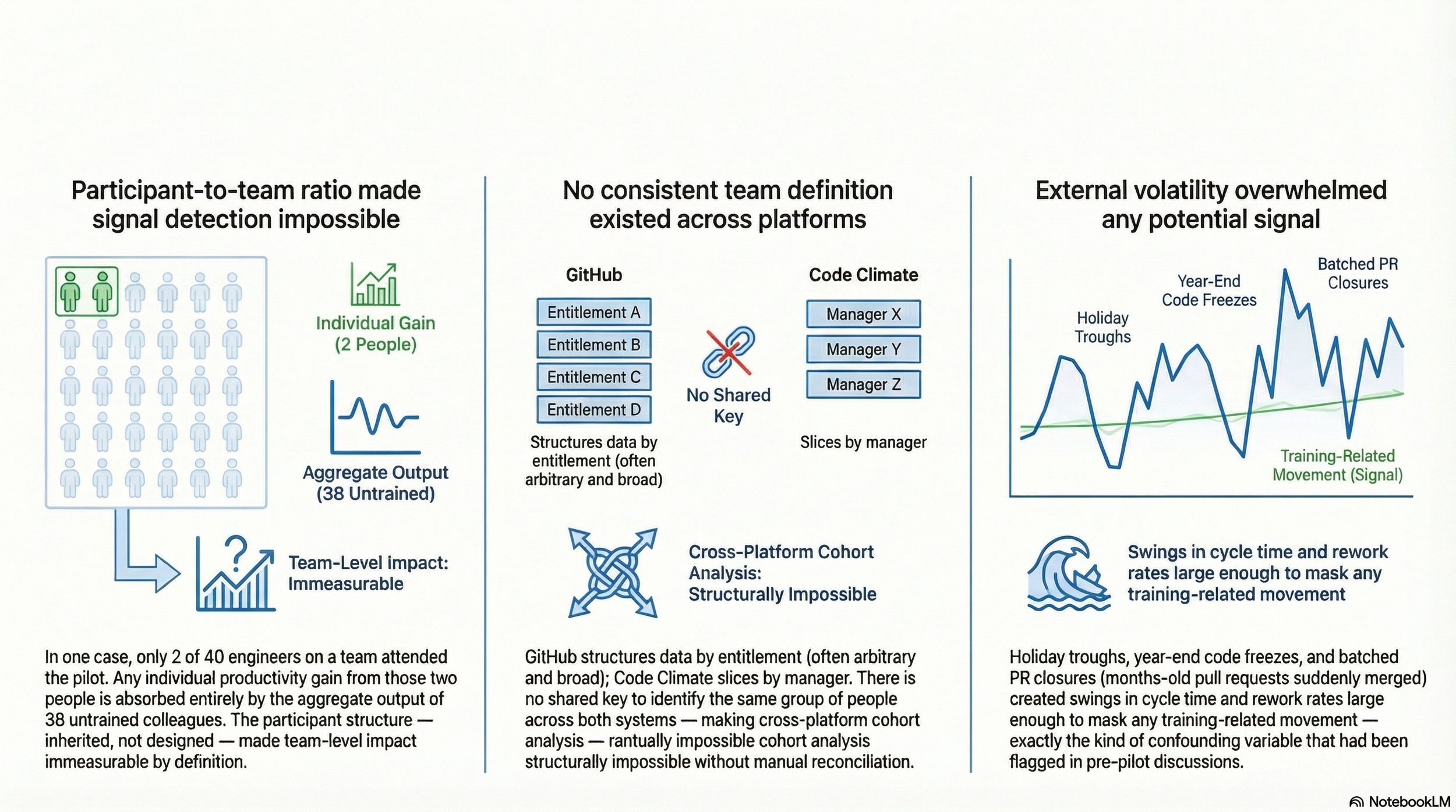
From null finding to forward-looking framework
01
02
04
Software Engineer Manager (Code Climate)
Platform owner best positioned to explain Code Climate’s data model, manager-based segmentation capabilities, and what cohort-level analysis was actually possible.
04 — ANALYSIS & SYNTHESIS
05 — KEY FINDINGS & INSIGHTS
Three systemic barriers confirmed
06 — IDEATION & ITERATION
The investigation's value wasn't in what the data showed — it was in what it enabled. A documented, stakeholder-facing null result with a clear causal explanation gives the organization something to act on: not just "it didn't work" but "here is precisely why, and here is what needs to change."
03
Train intact teams, not scattered individuals.
Benchmark teams against themselves.
Isolate training as the primary variable.
Avoid holiday and freeze windows.
07 — OUTCOMES & IMPACT
02
Before the pilot launched, informal discussions about using engineering metrics (Jira, GitHub, Code Climate) as ROI evidence were already circulating. I had prior experience attempting this exact type of analysis — including a formal investigation roughly a year earlier — and had already consulted with the DevOps team, whose view was that these metrics were unreliable for this purpose due to noise, inconsistent data structures, and attribution problems.
Drawing on that prior knowledge, I built a research plan with success metrics that stakeholders reviewed and agreed to. Critically, those conversations explicitly acknowledged that engineering platform metrics would be a stretch for measuring training effectiveness — too many variables sit outside a training program's control. This wasn't a hidden concern; it was documented and aligned on.
Systems Engineering Manager (GitHub/DevOps)
GitHub administrator who could speak to how entitlement-based access structures data, and why groups can range from a single team to hundreds of engineers under a broad category.
03
Software Engineer Manager (Pilot POC)
Point of contact for participant teams, who also ran an AI evaluation effort prior to the pilot. Their findings reached a similar conclusion through a completely different route, validating the credibility of my findings.
Cohesive teams who share a manager (or entitlement) become the unit of measurement — not a cross-departmental roster of enrolled engineers.
Establish a multi-sprint baseline before training begins. A team compared to its own pre-training performance is the only statistically valid approach — cross-team comparisons introduce too many uncontrolled variables.
When training is the only significant workflow change introduced to an intact team, observed metric shifts become attributable with greater confidence.
Measurement periods must represent standard operating cadence — not peak seasonal noise.
What this work produced
SUBSTANTIATED NULL RESULT
Transformed a pre-existing professional judgment into a documented, data-backed conclusion — giving stakeholders something concrete to reference rather than a researcher's opinion.
FORWARD-LOOKING FRAMEWORK
A five-part measurement strategy giving future program teams the structural conditions needed to generate credible ROI evidence at full rollout.
ONGOING DATA EXPLORATION
Participant rosters (with managers, teams, and repo links) passed to Code Climate analysts for further investigation into any residual signal in the data.
08 — REFLECTIONS & TAKEAWAYS
What this work reinforced
Measurement strategy is a design decision that must happen before a program launches.
This project is a case study in what happens when it doesn't, and a reminder that advocating for that sequencing early is part of the researcher's job, even when it's uncomfortable.
Doing the work anyway is sometimes the most credible move.
When stakeholders asked for a post-pilot investigation despite prior alignment on its limitations, the right response wasn't "we already discussed this." It was to document it rigorously enough that the finding could speak for itself and inform what comes next.
Working within inherited constraints requires adapting, not abandoning rigor.
I didn't control participant selection. I did control how I structured the cohort within those constraints, how I documented the risks, how I conducted the post-pilot analysis, and how I framed the path forward. That's where the research value lived.
Future opportunities for rollout goals and purpose surfaced with a new POV.
The reframe — "are we measuring whether a coder got faster, or whether the team delivered value sooner?" — points toward a more human-centered definition of training success. One that aligns with how agile teams actually operate and that makes the measurement architecture far more tractable at full rollout.